Start With How People Actually Find You Through AI
Before tracking prompts or building dashboards, it is necessary to understand how LLMs surface brands in the first place.
That starts with how users interact with AI.
- What problems are they trying to solve
- What context they bring into the prompt
- What assumptions the model makes based on prior knowledge
Prompt psychology matters here. Personalization matters. User intent matters. From a measurement standpoint, most of this is not directly trackable, and that is fine. This layer provides context, not metrics.
Take Amazon DynamoDB as an example.
Most users are not asking an AI tool, “What is Amazon DynamoDB?” That question exists, but it rarely determines influence. DynamoDB shows up when users are trying to solve infrastructure problems.
Common ways DynamoDB enters AI conversations:
- “What database should I use for a serverless application?”
- “Best database for unpredictable traffic spikes”
- “How do I build a globally distributed app without managing servers?”
- “DynamoDB vs Aurora for high-scale workloads”
In these prompts, DynamoDB is one option among several potential solutions.
How Those Conversations Change Over Time
The way a brand appears in AI responses is not static. It changes based on where the user is in their journey.
This is the part most LLM optimization efforts miss.
The same product can show up differently depending on whether someone is exploring a problem, evaluating options, or actively using the tool day to day. LLMs do not create that variation on their own. Users do.
Understanding this lifecycle is what turns prompt tracking from guesswork into signal.
LLM Usage Lifecycle
People use LLM platforms differently depending on their relationship with the problem and the product. An LLM optimization program accounts for each of these phases.
1. Problem Framing
At this stage, the user is not thinking about specific tools. They are trying to understand the problem itself.
They ask AI to help them name the challenge, understand tradeoffs, and identify possible solution types.
AI responses here shape which categories and approaches even get considered. If a product or approach does not appear at this stage, it never enters the mental shortlist.
This phase sets framing, not preference.
2. Solution Evaluation
Once the problem is clear, the user starts comparing options.
They ask AI to explain differences, surface risks, and clarify constraints. This is where brand names start appearing more consistently, but rarely in isolation.
Here, AI responses influence perceived fit. Honest tradeoffs matter more than positive framing. Overstated strengths at this stage create friction later.
3. Commitment and Setup
After a decision is made, the user shifts from evaluation to execution.
They use AI to confirm early design choices, understand best practices, and avoid obvious mistakes. Questions become more concrete and less exploratory.
This phase determines how confident the user feels about the decision they just made. Confusion here often leads to second guessing.
4. Active Use and Troubleshooting
Once the system is in production or active development, AI becomes part of daily workflow.
Users ask highly specific questions. They want direct answers that help them unblock work, fix issues, or improve performance.
Accuracy matters more than persuasion here. Incorrect or vague answers reduce trust in the product, even if the underlying issue is unrelated.
5. Expansion or Reconsideration
Over time, requirements change.
Users revisit earlier decisions as systems scale, new use cases emerge, or constraints become visible. AI is used to validate whether to expand usage, adjust architecture, or move in a different direction.
Clear guidance at this stage builds long-term credibility, even when the recommendation is not to continue.
Why This Matters for LLM Optimization
Most teams focus on the early moments, when users are discovering options.
In practice, influence is built across the entire lifecycle:
- Early phases shape awareness and framing
- Middle phases shape confidence and time to value
- Later phases shape trust, retention, and advocacy
An LLM optimization program maps prompts, content, and authority signals to each phase intentionally, instead of treating AI visibility as a single metric.
That is how context turns into a system and how AI becomes a durable growth channel.
To see how this works in practice, consider the types of questions users actually ask at each phase.
By mapping prompts to lifecycle stages, you can identify where awareness is built, where confidence is earned, and where trust is reinforced. This makes prompt tracking actionable rather than theoretical.
For Example: DynamoDB Prompts
1. Problem Framing
At this stage, users are exploring concepts and trying to understand the problem space.
- What database works best for serverless applications?
- How do you handle unpredictable traffic spikes in a database?
- Differences between relational databases and NoSQL databases?
- How does database latency affect user experience?
- Which database types are low-maintenance in the cloud?
2. Solution Evaluation
Users are now comparing DynamoDB to alternatives and assessing fit.
- DynamoDB vs Aurora for high-scale workloads
- When should you not use DynamoDB?
- Is DynamoDB a good choice for analytics workloads?
- DynamoDB vs MongoDB for serverless applications
- What are common tradeoffs with DynamoDB consistency models?
3. Commitment and Setup
The decision is made, and the user is getting started.
- How do I design DynamoDB partition keys effectively?
- Best practices for DynamoDB table design
- How to model many-to-many relationships in DynamoDB
- Avoiding hot partitions in DynamoDB
- Recommended approach for initial throughput settings
4. Active Use and Troubleshooting
Users are actively working with DynamoDB and need tactical guidance.
- Why is my DynamoDB query slow?
- How to troubleshoot hot partition issues
- How to check if an attribute exists in DynamoDB
- Optimizing DynamoDB read/write capacity
- How to monitor DynamoDB performance metrics
5. Expansion or Reconsideration
Users are reassessing or expanding usage as needs evolve.
- What are DynamoDB limitations at scale?
- When should I move off DynamoDB?
- Should I switch from DynamoDB to a relational database?
- How to combine DynamoDB with caching layers for performance
- Cost optimization for long-term DynamoDB usage
Use Prompts as Directional Signals
Tracked prompts act as a north star. They show how much category and question coverage for your brand compared to competitors. They help identify gaps, overlaps, and blind spots. Most importantly, they do not explain every personalized output an LLM may generate.
If a user mentions cost sensitivity, DynamoDB may be framed cautiously. If they mention burst traffic or global scale, it may be emphasized. If they mention analytics-heavy workloads, it may be deprioritized.
Each of these outputs are valid but personalization is infinite.
Tracking personalized paths does not provide a foundation to benchmark against the market.
A blank slate query provides a stable reference point. It shows how LLMs behave without memory, preferences, or prior context. That baseline is far more reliable for comparison and progress tracking than endlessly simulated personalization scenarios.
A clean, non-personalized prompt such as: “Best database for serverless applications”
creates a baseline. It shows whether DynamoDB appears, how it is framed, and which alternatives are presented alongside it. That baseline can be tracked over time and compared against competitors.
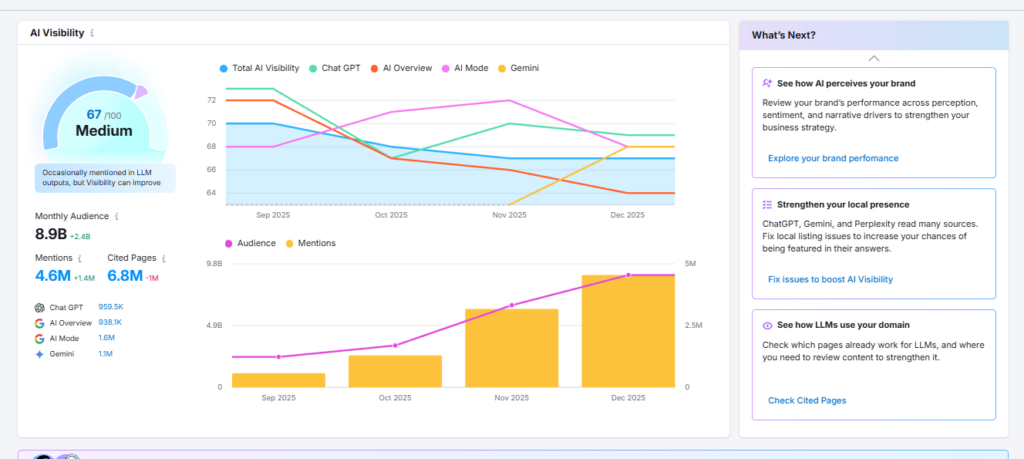
Tools can help here. Platforms like Semrush provide visibility into which prompts are surfacing brands. You can also track your specific prompts i
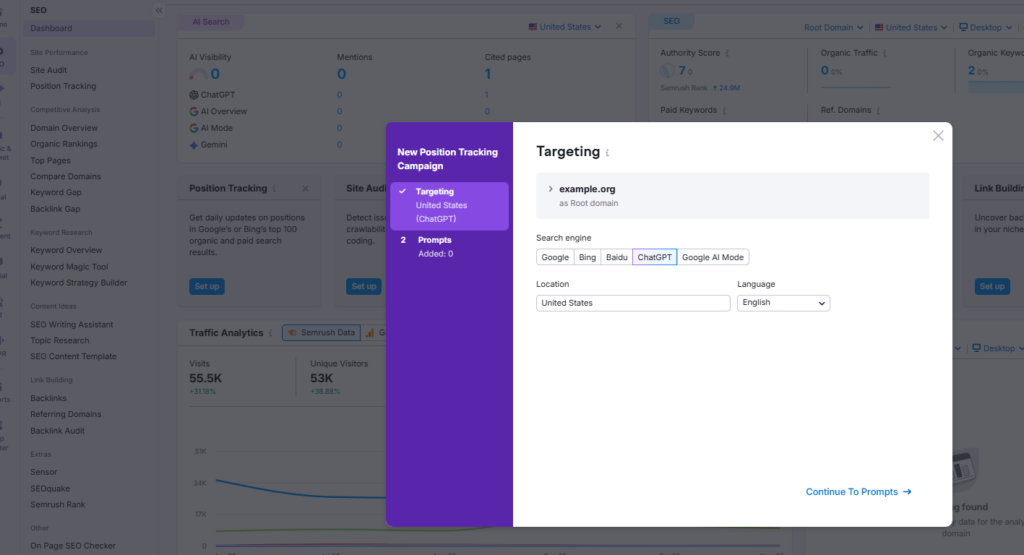
SEMRush has a relatively cost-efficient solution to prompt tracking that is easy to set up:
First create a new project with your website and begin setting up a position tracking module:
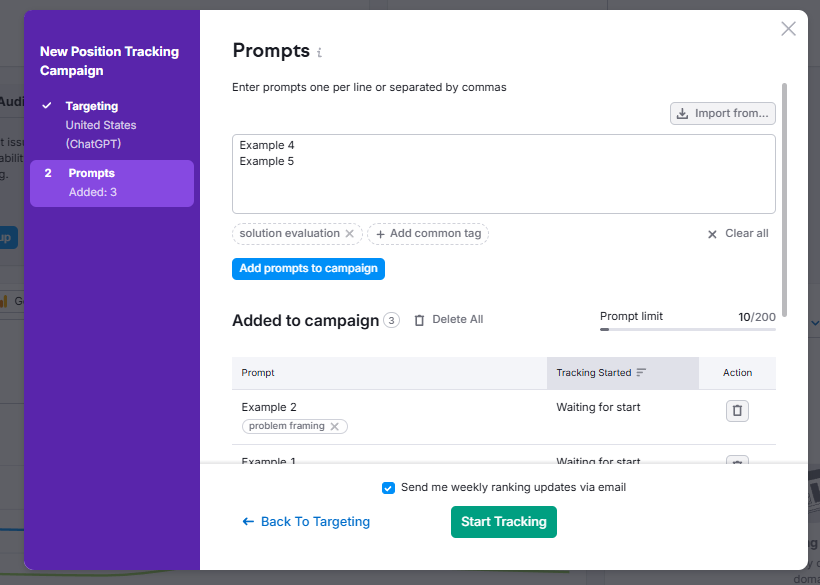
Then input the prompts relevant to your brand, both branded and unbranded prompts, and tag them with lifecycle tags.
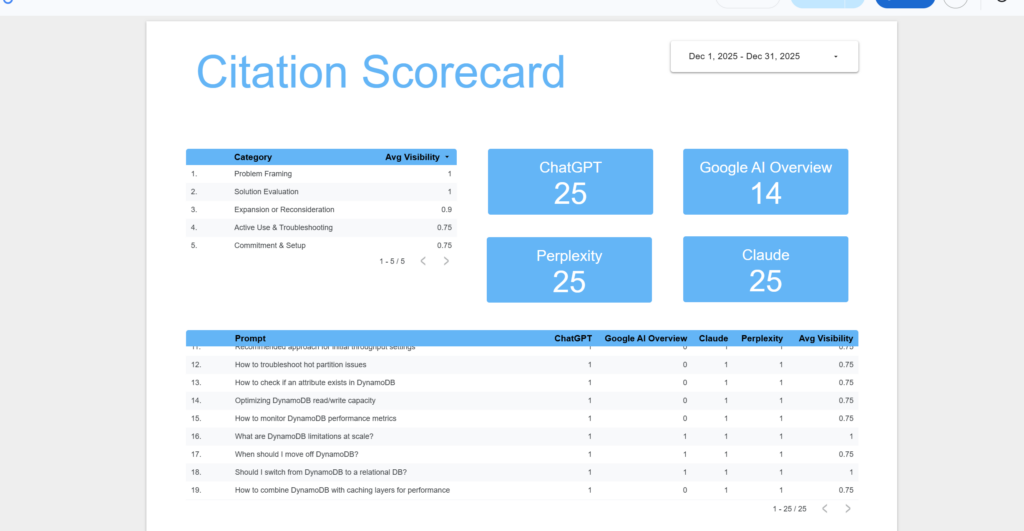
Whichever toolset you use, you can import the data into lookerstudio to build a scorecard for leadership updates.
How do LLMs Output Prompts?
Once you have a stable prompt set, the next question is how the LLM answers.
Not all AI answers are generated the same way.
Some responses are produced natively, based on the model’s internal knowledge and training data. Others trigger a process where the model expands the original prompt into multiple sub-queries, retrieves external sources (usually via search engines), and synthesizes an answer from what it finds.
This distinction matters because it determines where influence is created.
Two Common Output Patterns
Before deciding how to invest in content, it is necessary to understand which output pattern applies.

Native Model Output
In this mode, the AI responds without visible citations or external retrieval.
- Answers are framed confidently
- Sources are implicit, not referenced
- The response reflects what the model already “knows”
This usually happens for:
- Well-established concepts
- Widely documented patterns
- Topics with stable, repeated explanations
In these cases, influence is driven by long-term authority signals, consistency of framing, and how often the brand or concept appears in foundational material.
You do not optimize this layer by chasing keywords. You influence it by shaping how the category is understood over time. Technically, the more you influence the datasets that the LLM train on, the more likely you will appear in native outputs.
Query Fan Out
In this mode, the original prompt is expanded behind the scenes.
The AI breaks it into related sub-questions such as:
- Definitions
- Comparisons
- Constraints
Best practices
It then retrieves content across multiple sources via search engines and synthesizes an answer.
You will usually recognize this pattern when:
- Citations appear
- Multiple viewpoints are summarized
- The answer references specific claims or examples
This is where content strategy becomes tactical.
Why Query Fan Out Is the Action Layer
When query fan out is involved, the AI is no longer relying on general knowledge. It is actively looking for evidence.
That means:
- Each sub-query becomes a chance to influence the final answer
- Gaps in content translate directly into gaps in representation
- Weak explanations get replaced by stronger third-party framing
This is the layer where structured, question-driven content has outsized impact.
How to Use Query Fan Out to Guide Content Creation

Once you identify that a prompt triggers query fan out, the process becomes clearer.
- Decompose the Prompt
Break the original prompt into the implied sub-questions the AI needs to answer. These usually map to:- What it is
- When it applies
- How it works
- Limitations
- Alternatives
- Map Sub-Questions to Existing Content
identify which sub-questions you already cover clearly and which are being answered by external sources. - Fill the Gaps Intentionally
Create content that answers missing sub-questions directly, clearly, and without marketing language. - Follow Through With SEO
Implement SEO to rank your content on relevant search engines for the query fan out searches.
The goal is not to dominate every sub-query. It is to be the most legible source for the parts that matter most.
Why This Connects Back to Prompt Tracking
Prompt tracking tells you where you appear.
Query fan out tells you why you appear or disappear.
Together, they form a system:
- Prompts define the decision surface
- Output patterns reveal the influence mechanism
- Content fills the gaps LLMs cite
This is how LLM optimization moves from observation to execution, and how prompt data becomes a roadmap rather than a report.
From here, content strategy stops being about volume and starts being about coverage, clarity, and trust.
Crafting Content for Branded Prompts and Topics
Once you understand how prompts fan out and where answers are sourced, the next step is intentional content creation. This is where many teams default back to traditional SEO habits and lose the thread.
Branded prompts require a different approach.
A branded prompt is not just “What is [brand]?” It includes any question where the brand is implied, compared, validated, or stress-tested.
Examples include:
- “[Brand] limitations”
- “[Brand] vs alternatives”
- “How to do X with [brand]”
- “Should I use [brand] for Y”
These prompts appear most often in the evaluation, setup, and active use phases. The user already knows the brand exists. They are trying to decide whether to trust it, use it correctly, or continue using it.
What Branded Content Needs to Do
Content for branded prompts should prioritize clarity over persuasion.
It should:
- Answer the question directly, without deflection
- State constraints and tradeoffs explicitly
- Reflect real usage patterns, not idealized ones
- Match the language users use when they are stuck or uncertain
Creating Content for Citation
When query fan out is involved, LLM platforms assemble answers from multiple sources. Each source plays a role.
- Some provide definitions.
- Some explain mechanics.
- Some clarify limits or risks.
Your goal is not to win the entire answer. It is to be cited for the part you are best positioned to explain.
This requires content that is:
- Narrowly scoped to a specific question
- Structured so answers can be extracted cleanly
- Written in declarative language rather than narrative form
Well-crafted branded content often gets cited alongside competitors.
Measuring Citation Success With a Likeness Score
Traditional metrics like rankings or traffic do not show whether AI is representing your brand correctly. What matters is alignment, how closely AI outputs match the way you want your product or solution described. A practical way to track this is with a likeness score.
What a Likeness Score Measures
A likeness score compares AI-generated responses for a specific prompt to your reference content created to answer that prompt. It evaluates how closely the AI’s answer aligns in substance.
Key dimensions of alignment:
- Reference: Is your brand cited or clearly referenced when relevant?
- Framing: Does the AI describe the product consistently with your messaging?
- Text-for-Text: How alike was the output vs your actual content
Each dimension can be scored separately. A response can align well in some areas and poorly in others.
How to Measure It
- Run the prompt in a clean, non-personalized environment.
- Capture the AI-generated response.
- Compare it against the reference content for the same prompt.
- Score alignment across the dimensions above.
Why Prompt-Specific Content Matters
Generic documentation or broad marketing pages are not sufficient. To get meaningful results, each prompt should have dedicated content that:
- Answers the question clearly
- Frames the product accurately
- Defines boundaries and limitations
Without this, it is impossible to tell whether AI is reflecting your content or improvising based on external sources.

Why This Matters More Than Raw Mentions
A brand that appears frequently but inaccurately loses trust.
A brand that appears less often but consistently and correctly builds long-term influence.
Likeness scoring shifts focus away from visibility for its own sake and toward control over narrative. It shows whether content is actually shaping how LLM platforms explain the product to users at critical decision moments.
This closes the loop between prompt tracking, content creation, and measurement, turning LLM optimization into a system rather than a set of disconnected tactics.
What This Looks Like in Practice: DynamoDB
Consider a branded prompt such as:
“When should you not use DynamoDB?”
This is not a discovery question. The user already knows DynamoDB exists. They are validating risk and fit.
How the Answer Gets Built
In most LLMs, this prompt triggers query fan out.
Behind the scenes, the model looks for content that explains:
- DynamoDB’s access pattern constraints
- Tradeoffs between flexibility and scalability
- Cost behavior under certain workloads
- Common misuse scenarios
The final answer is assembled from whichever sources explain those points most clearly.
If AWS content avoids discussing limits, third-party blog posts fill the gap. If tradeoffs are explained inconsistently, the AI response becomes cautious or fragmented.
Crafting DynamoDB Content for Branded Prompts
To influence this answer, DynamoDB content needs to be explicit and narrow.
Effective DynamoDB content for branded prompts does things like:
- Clearly state that DynamoDB requires known access patterns
- Explain why ad hoc querying is not its strength
- Describe workloads where relational databases are a better fit
- Separate design constraints from operational advantages
This kind of content is not conversion-oriented. It is trust-oriented.
When DynamoDB’s own materials explain limitations plainly, they are more likely to be cited alongside third-party explanations.
Measuring DynamoDB Citation Success With a Likeness Score
Now look at the output vs relevant content created for the prompt.
A high likeness score would indicate that the AI answer:
- Correctly explains conditional expressions using exact or similar language as DynamoDB's documentation
- Uses DynamoDB terminology accurately
- Avoids suggesting unsupported query behavior
- Frames the solution as a normal pattern, not a workaround
A low likeness score would surface when the answer:
- Generates information not related to DynamoDb's documentation
- Confuses DynamoDB with non-related behavior
- Overgeneralizes database patterns
Both answers may mention DynamoDB. Only one represents it correctly.
** A major criticism in AEO and GEO is that all of this STILL DEPENDS ON TRADITIONAL SEO. The content you craft for specific prompts STILL NEED to be ranked highly across search engines to be referenced during the fan out. With branded content, the brand itself has more search equity and appears higher naturally.
Using UGC to Guide Content Creation
Many branded prompts rarely originate from marketing pages. They originate from confusion, friction, and debate.
If you want to understand the branded questions LLMs are most likely to surface and cite, you need to look where users ask questions when documentation falls short.
That means user-generated platforms.
Places like Reddit, G2, Capterra, Quora, GitHub issues, and community forums are training data proxies. They reflect how people actually talk about products when they are stuck, skeptical, or comparing options.
What to Look for in UGC Platforms
The goal is pattern recognition over sentiment analysis.
When reviewing UGC content, focus on:
- Repeated questions phrased in different ways
- Confusion around the same concepts
- Workarounds being shared instead of first-party guidance
- Disagreements about best practices
- Comments that start with “I wish I knew this earlier”
These patterns reveal friction points that LLMs will definitely reference when prompted.
Crawling UGC With Intent
UGC crawling should be scoped narrowly. You are not collecting everything. You are extracting signal.
A practical approach:
- Identify brand mentions combined with question language
- “How do I”
- “Why does”
- “Should I use”
- “Is it possible to”
- Group questions by underlying theme, not phrasing
- Limitations
- Cost surprises
- Setup mistakes
- Scaling issues
- Misaligned use cases
- Prioritize questions that appear across multiple platforms
- Reddit and G2
- Quora and forums
- Reviews and long-form discussions
Cross-platform repetition is a strong indicator of unresolved understanding.
To crawl, download instant data scraper and head over to a relevant forum (reddit/r/aws), then search for the 5 Ws
Open instant data scraper and clear columns except for URL, Thread Title, Votes, and Comments
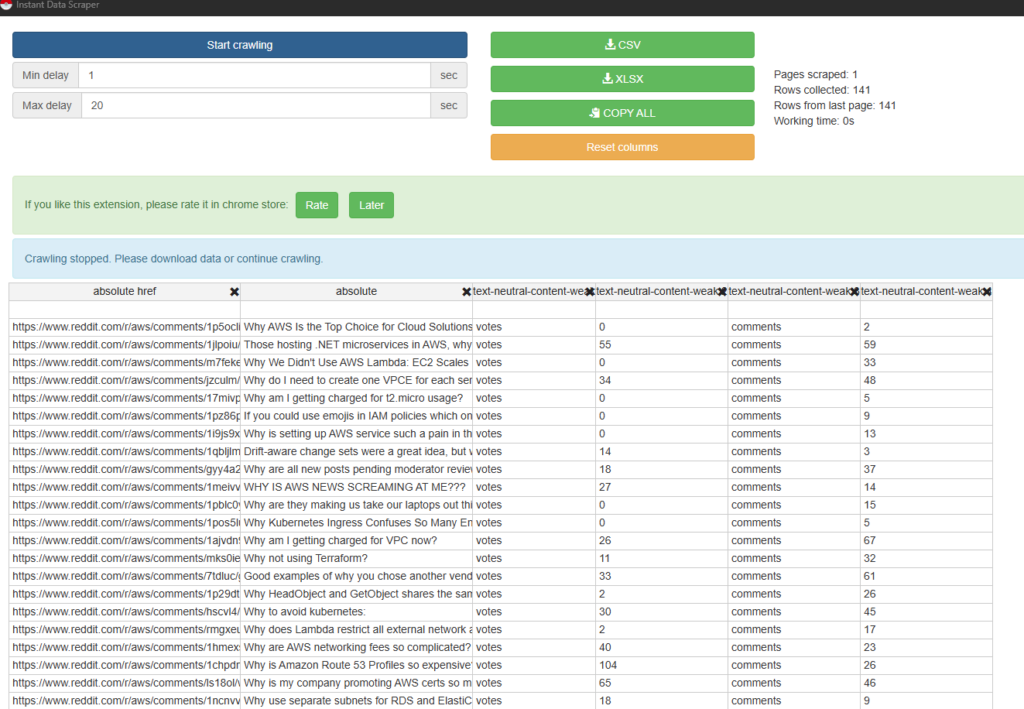
From here you can run analysis on which topics tend to show up more often, how much traction they get, and then formulate the UGC topics into content
Turning UGC Questions Into Branded Content
Once themes are clear, the next step is to create documented explanations that LLMs AND users (important) can rely on.
Effective branded content based on UGC:
- Answers the question directly without defensiveness
- Explains why the issue exists, not just how to fix it
- Distinguishes between misuse and real limitations
- Uses the same language users use in their questions
This content should be structured around the question itself, not buried inside feature pages.
When first-party content does that better than UGC threads, it becomes the citation (again, assuming SEO implementation kicks ass).
How This Improves Branded Prompt Performance
UGC-driven content improves branded prompts in three ways:
- Coverage
It fills gaps where LLMs would otherwise rely on third-party explanations. - Accuracy
It reduces misinterpretation caused by partial or outdated community advice. - Tone Alignment
It matches how users actually ask questions, which improves extractability during query fan out.
This is especially important for prompts like:
- “[Brand] limitations”
- “Why does [brand] behave this way”
- “Should I use [brand] for X”
These prompts are heavily influenced by community discourse.
Why This Matters
If you do not explain your product’s rough edges, the community will. If the community explains them inconsistently, LLMs inherit that inconsistency.
Using UGC as an input allows branded content to address reality rather than aspiration. That makes AI answers clearer, more accurate, and more trustworthy at the moments users are deciding whether to commit, continue, or walk away.
This is how branded prompt optimization becomes grounded in real user behavior instead of hypothetical queries.
Applying UGC-Driven Branded Content to DynamoDB
Many of the most influential DynamoDB questions are not asked on AWS documentation pages. They show up when developers are blocked, confused, or reconsidering earlier design choices.
That is why platforms like Reddit, Stack Overflow, GitHub issues, G2, Capterra, and Quora matter for DynamoDB. They surface as citation sources for LLMs when relevant prompts are asked.
What DynamoDB Questions Look Like in UGC
When you crawl UGC platforms for DynamoDB, the same themes appear repeatedly, often phrased differently:
- “Why can’t I query DynamoDB like a normal database?”
- “DynamoDB seems expensive, what am I doing wrong?”
- “How do I model relationships in DynamoDB without joins?”
- “Why is my DynamoDB table throttling?”
- “Should I be using DynamoDB for this at all?”
These represent common friction points during setup, scaling, and long-term usage.
When these questions lack clear first-party explanations, LLMs cite the community’s mixed answers.
Crawling DynamoDB UGC With Intent
For DynamoDB, UGC crawling should focus on usage confusion rather than feature announcements.
A practical crawl strategy includes:
- Reddit threads in r/aws, r/devops, and r/serverless
- Stack Overflow questions tagged with DynamoDB
- GitHub issues and discussions for AWS SDKs
- G2 and Capterra reviews mentioning limitations or cost
- Quora questions comparing DynamoDB to relational databases
Key signals to extract:
- Questions that repeat across platforms
- Comments that contradict each other
- Advice that includes workarounds instead of explanations
- Posts that warn others away without context
Turning DynamoDB UGC Into Site Content
The goal is to create authoritative explanations that can be cited along with UGC platforms assuming that SEO has been implemented.
Examples of DynamoDB content derived from UGC:
- Explains why partition keys are required, not just how to use them
- Clarifies when scans are acceptable and when they are not
- Describes cost behavior tied to access patterns
- States clearly when DynamoDB is the wrong tool
This content should be structured around the question itself:
- One question per page or section
- Direct answers first
- Constraints and tradeoffs stated plainly
When DynamoDB documentation and guidance do this well, they can get cited more often than community threads.
Influencing UGC Where AI Cites
When an LLM answers a branded prompt, it often pulls from the most legible, confident, and repeated explanations available. In many cases, those explanations come from Reddit threads, Stack Overflow answers, GitHub issues, and long-form forum discussions.
This creates an opportunity and a responsibility.
Brands cannot control UGC.
But they can participate intentionally.
The Role of the Internal Ambassador
Effective participation in online discussions comes from real practitioners.
An internal ambassador is someone who:
- Understands the product deeply
- Can explain tradeoffs without defensiveness
- Speaks the language users use when they are stuck
- Is comfortable saying “this is a limitation” when it is
This person may be an engineer, PM, solutions architect, or support lead. Title matters less than credibility.
Their role is not promotion. Instead, the internal ambassador should be the first to respond to prioritized questions asked on community and ugc platforms.
Where and When to Engage
Not every thread deserves a response. Engagement should be selective and intentional.
High-priority situations include:
- Questions with high visibility or upvotes
- Threads where incorrect explanations are gaining traction
- Repeated confusion around the same topic
- “Should I use X?” or “Why does X behave this way?” discussions
Low-value engagement includes:
- Feature requests without context
- Opinion-only debates
- Threads already resolved with accurate explanations
The goal is not volume. It is signal correction.
How to Respond Without Sounding Like Marketing
Tone determines whether a response gets trusted or ignored.
Effective responses share common traits:
- They answer the question directly
- They acknowledge limitations early
- They explain why something behaves the way it does
- They avoid links unless it references specific documentation meant to resolve the question
- They do not redirect to sales or product pages
Bad responses try to “reframe” the question.
Good responses reduce confusion.
Why This Matters for LLM Outputs
LLMs favor explanations that are:
- Concrete
- Confident
- Repeated across sources
A single authoritative response will not change model behavior.
But consistent, high-quality explanations across time do.
When internal ambassadors clarify the same concepts repeatedly:
- Misleading community explanations lose dominance
- Accurate framing becomes the default
- LLMs inherit that framing during query fan out
This is indirect influence, but it compounds.
Internal Process for Managing UGC Engagement
UGC participation needs structure or it becomes ad hoc and reactive.
A lightweight internal process works best.
A simple Kanban-style flow is sufficient:
Incoming
- Threads flagged by support, community, or SEO teams
- High-impression or high-confusion posts
Triage
- Is the question recurring?
- Is the explanation incorrect or incomplete?
- Is this a branded prompt risk?
Respond
- Assign to the appropriate SME
- Respond once, clearly, and without marketing
Document
- Capture the question and explanation internally
- Use it as input for first-party content
Close the Loop
- Decide whether this question warrants:
- Dedicated documentation
- A new prompt-specific page
- Clarification in existing guides
What Not to Do
A few common mistakes weaken credibility fast:
- Arguing with users
- Defending the product instead of explaining it
- Overusing official branding language
- Dropping links without context
- Responding too late, after misinformation spreads
Silence is sometimes better than a bad response.
How This Connects Back to Branded Prompt Coverage
UGC responses and first-party content reinforce each other.
When an internal ambassador explains a limitation clearly:
- That explanation can be turned into site content
- That content can rank and get cited during query fan out
- Future UGC threads can reference it
- LLMs inherit a stable explanation across sources
This closes the loop between:
- community reality
- first-party documentation
- AI-generated answers
Why This Matters Long Term
If a brand does not participate in UGC conversations, it forfeits the narrative to whoever speaks loudest or earliest.
When brands participate carefully, honestly, and consistently:
- Users trust the explanations more
- Community discourse stabilizes
- LLM outputs become clearer and less defensive
Crafting Content for Unbranded Prompts and Topics
How Unbranded Prompts Work
Unbranded prompts are questions where the user has not named a product yet. They are asking about problems, approaches, or categories.
Examples include:
- “Best database for serverless applications”
- “How to handle unpredictable traffic spikes”
- “How to design a globally distributed system”
- “Database options for low operational overhead”
At this stage, the user is not evaluating brands. They are forming a mental model of what solutions exist.
LLMs respond by assembling an answer from:
- category explanations,
- architectural patterns,
- comparative discussions,
- commonly cited examples.
If your product is not embedded in those explanations, it never enters the conversation later.
The Goal of Content for Unbranded Prompts
Your goal is to make sure that when an LLM explains:
- a problem,
- a pattern,
- or a decision type,
your product is a natural example and citation.
This means content should:
- Explain the problem clearly before introducing solutions
- Describe solution categories, not just features
- Include your product as a representative option where appropriate
- Avoid brand-first framing
LLMs are far more likely to cite content that teaches than content that pitches.
How Content Gets Used During Query Fan Out
When an unbranded prompt triggers query fan out, the LLM looks for sources that answer questions like:
- What kinds of solutions exist?
- What tradeoffs define each approach?
- What patterns are commonly used?
- Which tools are known for which strengths?
Each of these sub-questions becomes a retrieval opportunity.
If your content only exists under branded pages, the LLM will rely on third-party explanations to answer these questions, even if your product is the best fit.
Structuring Content for LLMs
Effective content tends to share a few traits:
- Problem-led headlines
- Clear definitions before recommendations
- Explicit tradeoffs between approaches
- Examples that feel instructional, not promotional
- And SOLID SEO Implementation, both onpage and offpage
For Example: How Unbranded Prompts Introduces DynamoDB Into AI Answers
Consider an unbranded prompt such as:
“Best database for a serverless application”
At face value, this is not a DynamoDB question. The user has not mentioned AWS, NoSQL, or any specific product. They are asking about an architectural decision.
What the LLM Needs to Answer
To respond, the model must assemble an explanation that includes:
- What “serverless” implies for data storage
- Which database characteristics matter in this context
- What tradeoffs exist between different approaches
- Examples of tools that match those constraints
How Query Fan Out Pulls DynamoDB Into the Answer
Behind the scenes, the LLM expands the prompt into sub-queries such as:
best database for distributed applications
serverless database comparison
secure database for serverless applications
affordable database for serverless applications
If authoritative content exists that explains these patterns clearly and uses DynamoDB as an example, DynamoDB becomes part of the answer naturally.
The Difference Between Being Mentioned and Being Framed
There is a meaningful distinction here.
DynamoDB can appear in an answer in two ways:
- As a name in a list of options
- As the reference point for a specific category
ie. content that simply says “DynamoDB is a NoSQL database”
Content that explains:
- why serverless workloads benefit from managed scaling,
- why access-pattern-driven design matters,
- why low operational overhead changes architectural decisions,
allows DynamoDB to be framed as the default example for that category.
Why This Matters for LLM Optimization
If DynamoDB does not appear in unbranded prompts, it never reaches evaluation.
If it appears without clear framing, branded prompts become defensive.
Content is where:
- categories are defined,
- defaults are established,
- and solution types are normalized.
That is how LLM optimization moves upstream and why content optimized for non-branded prompts is not optional.
Tracking Impact From AI Visibility to Revenue
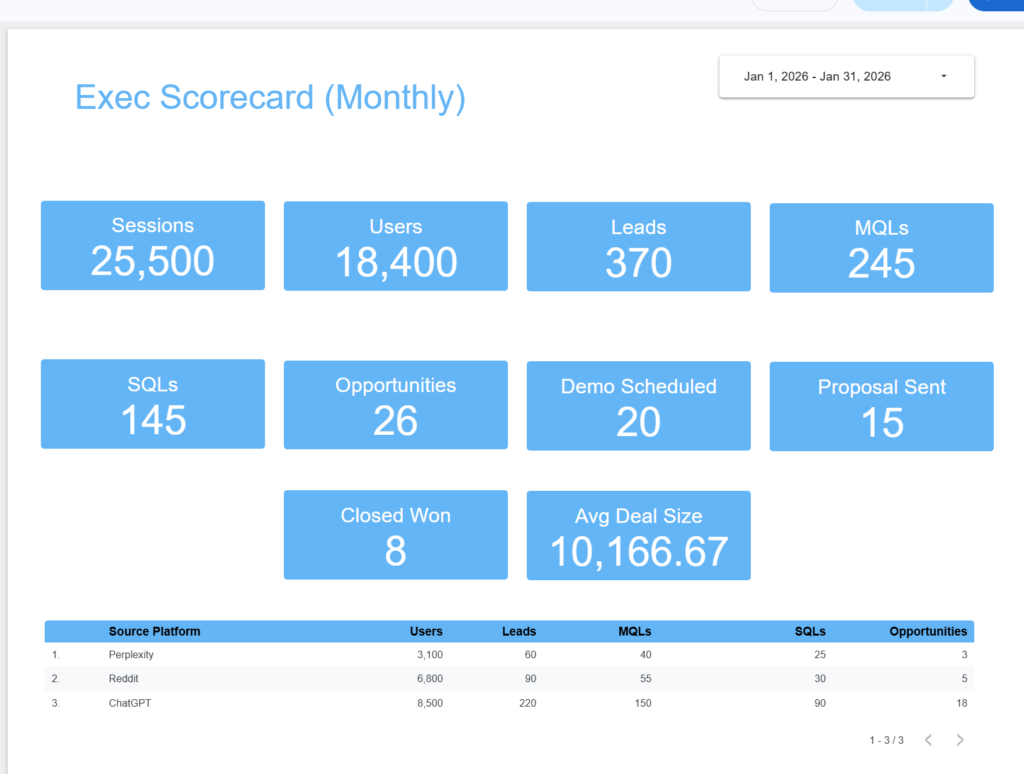
LLM optimization does not replace traditional measurement.
It changes where signal appears first.
The mistake teams make is trying to force direct attribution too early. A real program tracks leading indicators first, then follows impact downstream through analytics and revenue systems.
First-Line Signals: Prompt Visibility Platforms
Platforms like Profound and Semrush sit at the top of the measurement stack.
They do not measure outcomes.
They measure exposure and framing.
These tools help answer questions like:
- Which prompts surface the brand?
- How often does the brand appear relative to competitors?
- How is the brand described when it appears?
- Which prompts are gaining or losing visibility over time?
These are leading indicators. They tell you whether your brand is entering AI conversations and whether content changes are affecting inclusion and framing.
If visibility does not improve here, downstream metrics will not move.
Behavioral Confirmation
Once prompt-level visibility shifts, the next signal appears in **user behavior.
GA4 or other analytics platforms (Adobe analytics probably) becomes the bridge between AI exposure and business impact.
Relevant leading indicators include:
- Sessions from AI-referral sources
- Session from UGC referral Sources
- Users arriving from AI platforms
- Engagement patterns of AI-referred users
- Landing pages entered via AI-driven discovery
At this stage, you are validating that AI visibility is changing how users arrive.
Lagging Indicators: Leads and MQLs
After behavioral shifts appear, it makes sense to look at funnel metrics.
This is where AI influence begins to show up indirectly.
Common indicators include:
- Leads attributed to AI-referred sessions
- MQL volume from AI-driven traffic
- Conversion rate differences between AI and non-AI users
These are lagging indicators. They move slower and with more noise, but they confirm that upstream visibility is reaching buyers.
You should pull these by using the source platform to marry your GA4 data with your CRM data.
That way, you can track sessions and users to leads and beyond.
Breaking Down the MQL Funnel
For teams with mature revenue ops, the signal does not stop at MQL.
Continuing with CRM data, breaking down the MQL funnel helps you figure out where prospects are getting caught up. This opens up opportunities to optimize elsewhere in the overall marketing plan.
A more useful view tracks how AI-influenced leads move through the qualification funnel:
- MQL
- Connected
- Discovery
- SQL
This helps answer an important question:
Are AI-influenced leads progressing at the same rate, faster, or slower than other sources?
Quality matters more than volume here.
From SQL to Revenue
Finally, impact shows up in the sales funnel itself.
Typical stages include:
- Opportunities
- Demo scheduled
- Demo completed
- Proposal sent
- Negotiation
- Contract sent
- Closed won
- Revenue
At this point, AI influence is fully lagging and signals whether early framing and trust shortened cycles, improved fit, or reduced friction.
How to Read This Funnel Correctly
This is not a straight attribution chain.
Prompt visibility does not “cause” revenue in a clean line.
Instead:
- Prompt platforms signal presence
- GA4 signals attention
- CRM signals commitment
- Revenue signals fit
Each layer validates the one above it.
Trying to skip layers leads to false conclusions.
Why This Measurement Model Works
This approach respects how AI actually influences decisions.
AI shapes:
- What gets considered
- How options are framed
- Which tradeoffs feel acceptable
Those effects show up early in prompts, then slowly downstream in behavior and revenue.
A real LLM optimization program tracks the entire signal chain, not just the endpoint.
That is how AI visibility becomes a measurable growth input instead of a speculative channel.